



Description
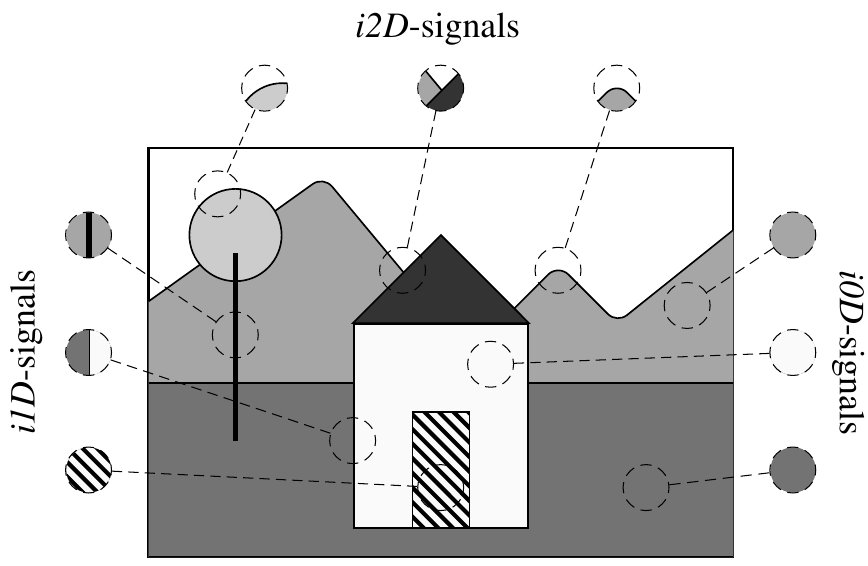
We present a demonstration of a deep learning model designed to predict human fixation patterns across visual scenes. The model estimates the fixation density over an image, representing the probability distribution of where viewers are likely to focus their gaze. This prediction is informed by a biologically inspired feature set based on intrinsically two-dimensional (I2D) signals—image regions characterized by local structures such as corners, intersections, and curvatures, which are known to be particularly informative for visual perception. In contrast to intrinsically one-dimensional (I1D) features like edges or lines, and intrinsically zero-dimensional (I0D) features such as flat regions of constant luminance, I2D features have been shown to be strong predictors of fixation locations in human observers. (Zetsche, Krieger, 2001)
The architecture of the model builds on a modern convolutional network tailored for image analysis. It integrates pre-computed I2D feature maps, derived via FFT-based curvature filters, with learned convolutional representations. These handcrafted and learned features are fused across multiple stages of the backbone network. A dedicated prediction head, composed of convolutional layers followed by a multilayer perceptron (MLP), aggregates these multiscale features to produce a dense saliency map. This architecture allows the model to leverage both biologically plausible signals and deep learned representations, yielding accurate and interpretable predictions of visual attention.
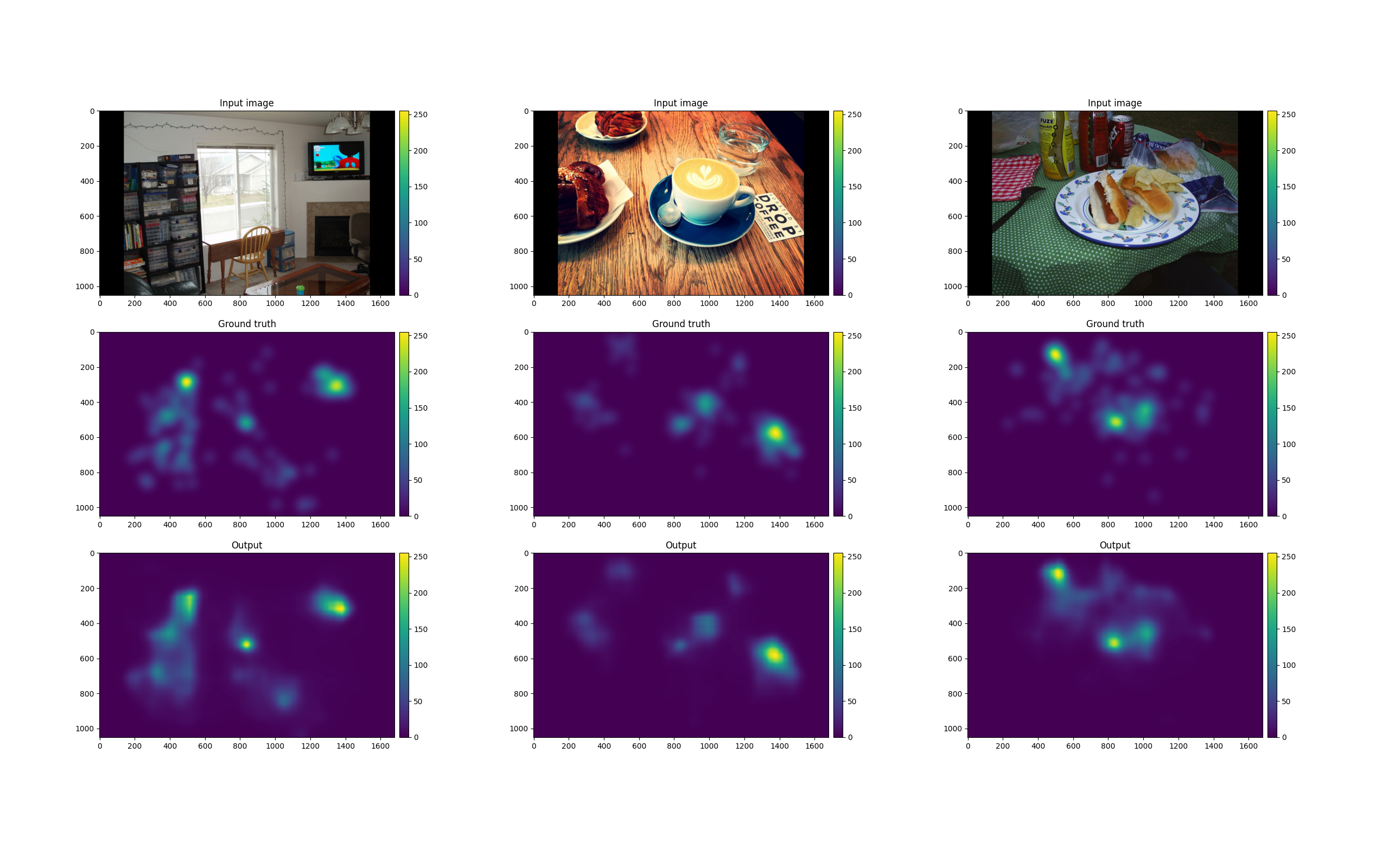
Example outputs of the model (input images taken from Coco Freeview dataset).
Author and Contact Details
- Dr.-Ing. Konrad Gadzicki
Email: gadzicki@uni-bremen.de
Profile: Dr.-Ing. Konrad Gadzicki - Dr.-Ing. Jaime Maldonado
Email: jmaldonado@uni-bremen.de
Profile: Dr.-Ing. Jaime Maldonado