



Description
This laboratory focuses on advancing robotic capabilities in performing core actions such as cutting, mixing, pouring, and transporting within dynamic, human-centered environments like homes.
Every time we think that we are getting a little bit closer to a household robot, new research comes out showing just how far we have to go. Certainly, we have seen a lot of progress in specific areas like grasping and semantic understanding etc., but putting it all together into a hardware platform that can actually do things autonomously still seems to be a long way to go. In a paper presented at ICRA 2021, researchers from the University of Bremen conducted a “Robot Household Marathon Experiment,” where a PR2 robot was tasked with first setting a table for a simple breakfast and then cleaning up afterwards in order to “investigate and evaluate the scalability and the robustness aspects of mobile manipulation.” While this may seem like something robots should have figured out, you might not be surprised to learn that it is actually still a significant challenge.
Parameterizing General Action Plans with Web Knowledge
To enable robotic agents to handle unknown task variations by parameterizing general action plans using web knowledge, we employ a specific architecture. The robot accesses a general action designator of cutting that can be parameterized. Upon receiving a task request, it can query the graph database with the knowledge graph directly via its SPARQL REST API or use a knowledge framework with additional functionalities such as the KnowRob knowledge processing system and pose Prolog queries, which are then translated to SPARQL queries.
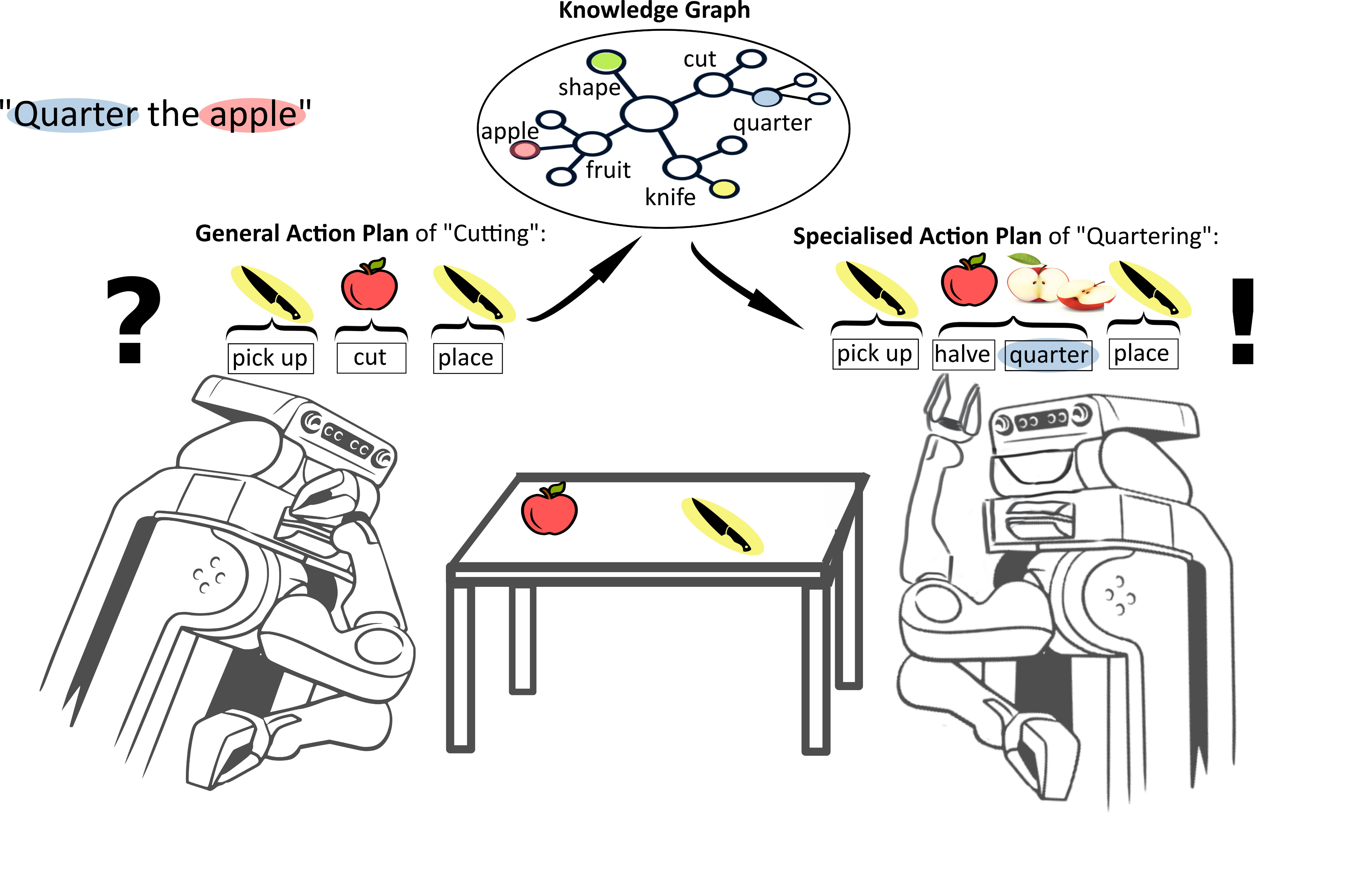
In general, the robot needs to have access to a general action designator of cutting that can be parameterised. When the robot is given a task request, it can either query the graph database with the knowledge graph directly via its SPARQL REST API or use a knowledge framework with additional functionalities such as the KnowRob knowledge processing system3 and pose Prolog queries, which then are translated to SPARQL queries. More information on the different ways of querying the knowledge graph can be found here.
Gathering and Linking Web Knowledge
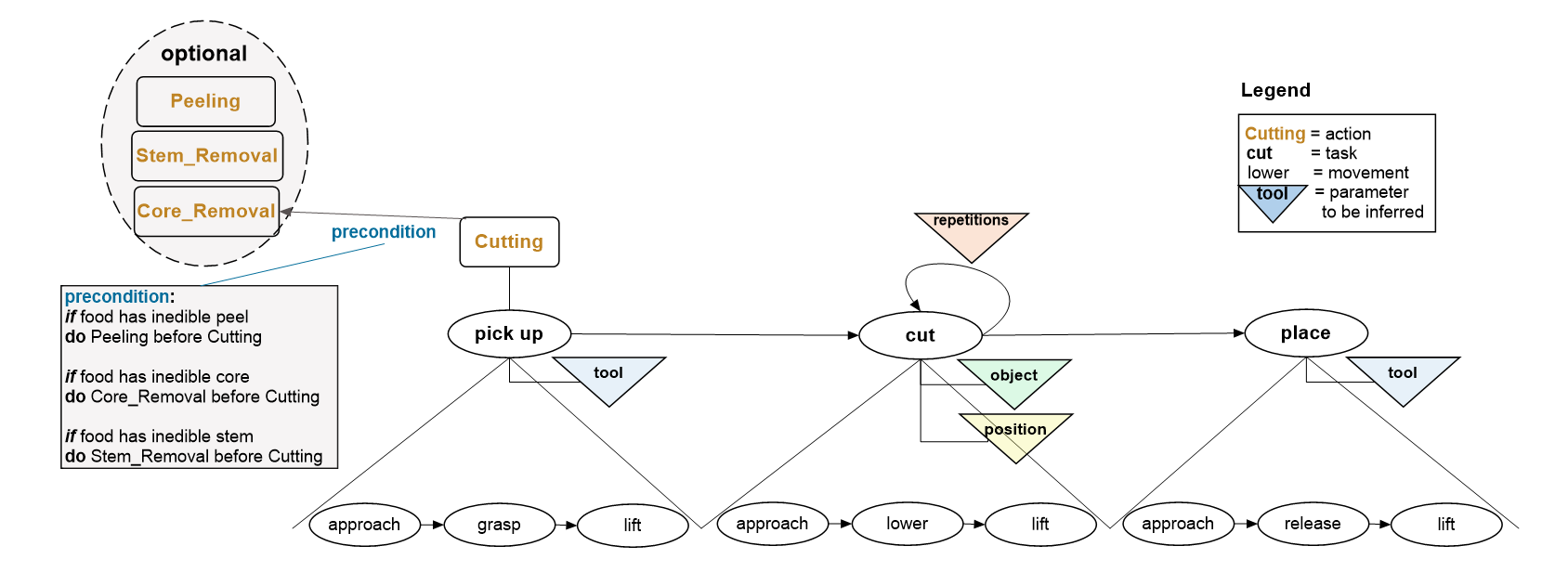
To support robotic agents in executing variations of cutting on different fruits and vegetables, we collect two types of knowledge in our knowledge graph: action and object knowledge. Both kinds of knowledge need to be linked to enable task execution. Action knowledge covers all properties of a specific manipulation action necessary for successful completion, influenced by the participating objects. Object knowledge includes all relevant information about the objects involved in the task execution, such as tools, containers, and targets.
Object Knowledge
As the name suggests, object knowledge covers all relevant information about the objects involved in the task execution (e.g. tools, containers, targets). Of course, the relevance of each piece of information depends on the task to be executed. So, for the task of ”Cutting an apple", the apple’s size or anatomical structure is relevant, but whether it is biodegradable or not is irrelevant.
For the target group of fruits & vegetables, we gather the following information in our knowledge graph:
- food classes (e.g. stone fruit or citrus fruit)
- fruits and vegetables
- anatomical parts
- edibility of the anatomical parts
- tool to remove the anatomical parts
We gather these information from structured sources like FoodOn8 and the PlantOntology9, but also from unstructured sources like Recipe1M+10 or wikihow.
In total, the knowledge graph contains:
- 6 food classes
- 18 fruits & 1 vegetable
- 4 anatomical parts (core, peel, stem, shell)
- 3 edibility classes (edible, should be avoided, must be avoided)
- 5 tools (nutcracker, knife, spoon, peeler, hand)

In general, a disposition describes the property of an object, thereby enabling an agent to perform a certain task11 as in a knife can be used for cutting, whereas an affordance describes what an object or the environment offers an agent12 as in an apple affords to be cut. Both concepts are set in relation by stating that dispositions allow objects to participate in events, realising affordances that are more abstract descriptions of dispositions3. In our concrete knowledge graph, this is done by using the affordsTask, affordsTrigger and hasDisposition relations introduced in the SOMA ontology3.
With these actions and their parameters, you can instantiate the Action Core Lab and simulate a robot to perform the action.
Example Video
Authors and Contact Details
- Dr. Michaela Kümpel
Tel: +49 421 218 64021
Email: michaela.kuempel@cs.uni-bremen.de
Profile: Michaela Kuempel - Vanessa Hassouna
Tel: +49 421 218 99651
Email: hassouna@cs.uni-bremen.de
Profile: Vanessa Hassouna - Prof. Michael Beetz, PhD
Head of Institute
Tel: +49 421 218 64001
Email: beetz@cs.uni-bremen.de
Profile: Michael Beetz
please cite this work with this:
@inproceedings{kuempel2024methodology,
title={Towards a Knowledge Engineering Methodology for Flexible Robot Manipulation in Everyday Tasks},
author={Kümpel, Michaela and Töberg, Jan-Phillip and Hassouna, Vanessa and Cimiano, Phillip and Beetz, Michael},
booktitle={Actionable Knowledge Representation and Reasoning for Robots (AKR^3) at European Semantic Web Conference (ESWC)},
year={2024},
url={https://ceur-ws.org/Vol-3749/akr3-04.pdf},
}
Publications
- L. Zhang, Q. Lyu, and C. Callison-Burch, ‘Reasoning about Goals, Steps, and Temporal Ordering with WikiHow’, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online: Association for Computational Linguistics, 2020, pp. 4630–4639. doi: 10.18653/v1/2020.emnlp-main.374.
- C. D. Manning, M. Surdeanu, J. Bauer, J. Finkel, S. J. Bethard, and D. McClosky, ‘The Stanford CoreNLP Natural Language Processing Toolkit’, in Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2014, pp. 55–60. Online
- D. Beßler et al., ‘Foundations of the Socio-physical Model of Activities (SOMA) for Autonomous Robotic Agents’, in Formal Ontology in Information Systems, vol. 344, IOS Press, 2022, pp. 159–174. Accessed: Jul. 25, 2022. doi: 10.3233/FAIA210379.
- V. Presutti and A. Gangemi, ‘Dolce+ D&S Ultralite and its main ontology design patterns’, in Ontology Engineering with Ontology Design Patterns: Foundations and Applications, P. Hitzler, A. Gangemi, K. Janowicz, A. Krisnadhi, and V. Presutti, Eds. AKA GmbH Berlin, 2016, pp. 81–103.
- G. A. Miller, ‘WordNet: A Lexical Database for English’, Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995, doi: 10.1145/219717.219748.
- K. K. Schuler, ‘VerbNet: A broad-coverage, comprehensive verb lexicon’, PhD Thesis, University of Pennsylvania, 2005.
- C. F. Baker, C. J. Fillmore, and J. B. Lowe, ‘The Berkeley FrameNet Project’, in Proceedings of the 36th annual meeting on Association for Computational Linguistics -, Montreal, Quebec, Canada: Association for Computational Linguistics, 1998, p. 86. doi: 10.3115/980845.980860.
- D. M. Dooley et al., ‘FoodOn: a harmonized food ontology to increase global food traceability, quality control and data integration’, npj Sci Food, vol. 2, no. 1, Art. no. 1, Dec. 2018, doi: 10.1038/s41538-018-0032-6.
- P. Jaiswal et al., ‘Plant Ontology (PO): a Controlled Vocabulary of Plant Structures and Growth Stages’, Comparative and Functional Genomics, vol. 6, no. 7–8, pp. 388–397, 2005, doi: 10.1002/cfg.496.
- J. Marín et al., ‘Recipe1M+: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images’, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, pp. 187–203, Jan. 2021, doi: 10.1109/TPAMI.2019.2927476.
- M. T. Turvey, ‘Ecological foundations of cognition: Invariants of perception and action.’, in Cognition: Conceptual and methodological issues., H. L. Pick, P. W. van den Broek, and D. C. Knill, Eds. Washington: American Psychological Association, 1992, pp. 85–117. doi: 10.1037/10564-004.
- M. H. Bornstein and J. J. Gibson, ‘The Ecological Approach to Visual Perception’, The Journal of Aesthetics and Art Criticism, vol. 39, no. 2, p. 203, 1980, doi: 10.2307/429816.